




2月16日,OpenAI的AI视频模型Sora炸裂出道,生成的视频无论是清晰度、连贯性和时间上都令人惊艳,一时间,诸如“现实不存在了!”的评论在全网刷屏。
Sora是如何实现如此颠覆性的能力的呢?这就不得不提到其背后的两项核心技术突破——Spacetime Patch(时空Patch)技术和Diffusion Transformer(DiT,或扩散型Transformer)架构。

查询这两项技术的原作论文,时空Patch的技术论文实际上是由谷歌DeepMind的科学家们于2023年7月发表的。DiT架构技术论文的一作则是Sora团队领导者之一William Peebles,但戏剧性的是,这篇论文曾在2023年的计算机视觉会议上因“缺少创新性”而遭到拒绝,仅仅1年之后,就成为Sora的核心理论之一。
如今,Sora团队毫无疑问已经成为世界上最受关注的技术团队。OpenAI官网显示,Sora团队由Peebles等3人领导,核心成员包括12人,其中有多位华人。值得注意的是,这支团队十分年轻,成立时间还尚未超过1年。

核心突破一:
时空Patch,站在谷歌肩膀上
此前,OpenAI在X平台上展示了Sora将静态图像转换为动态视频的几个案例,其逼真程度令人惊叹。Sora是如何做到这一点的呢?这就不得不提到该AI视频模型背后的两项核心技术——DiT架构和Spacetime Patch(时空Patch)。
据外媒报道,Spacetime Patch是Sora创新的核心之一,该项技术是建立在谷歌DeepMind对NaViT(原生分辨率视觉Transformer)和ViT(视觉Transformer)的早期研究基础上。
Patch可以理解为Sora的基本单元,就像GPT-4的基本单元是Token。Token是文字的片段,Patch则是视频的片段。GPT-4被训练以处理一串Token,并预测出下一个Token。Sora遵循相同的逻辑,可以处理一系列的Patch,并预测出序列中的下一个Patch。
Sora之所以能实现突破,在于其通过Spacetime Patch将视频视为补丁序列,Sora保持了原始的宽高比和分辨率,类似于NaViT对图像的处理。这对于捕捉视觉数据的真正本质至关重要,使模型能够从更准确的表达中学习,从而赋予Sora近乎完美的准确性。由此,Sora能够有效地处理各种视觉数据,而无需调整大小或填充等预处理步骤。
OpenAI发布的Sora技术报告中透露了Sora的主要理论基础,其中Patch的技术论文名为Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution。该篇研究论文是由谷歌DeepMind的科学家们于2023年7月发表的。

核心突破二:
扩散型Transformer架构
相关论文曾遭拒绝
除此之外,Sora的另一个重大突破是其所使用的架构,传统的文本到视频模型(Runway、Stable Diffusion)通常是扩散模型(Diffusion Model),文本模型例如GPT-4则是Transformer模型,而Sora则采用了DiT架构,融合了前述两者的特性。
据报道,传统的扩散模型的训练过程是通过多个步骤逐渐向图片增加噪点,直到图片变成完全无结构的噪点图片,然后在生成图片时,逐步减少噪点,直到还原出一张清晰的图片。Sora采用的架构是通过Transformer的编码器-解码器架构处理包含噪点的输入图像,并在每一步预测出更清晰的图像。DiT架构结合时空Patch,让Sora能够在更多的数据上进行训练,输出质量也得到大幅提高。
OpenAI发布的Sora技术报告透露,Sora采用的DiT架构是基于一篇名为Scalable diffusion models with transformers的学术论文。预印本网站arxiv显示,该篇原作论文是2022年12月由伯克利大学研究人员William (Bill) Peebles和纽约大学的一位研究人员谢赛宁共同发表。William (Bill) Peebles之后加入了OpenAI,领导Sora技术团队。

然而,戏剧化的是,Meta的AI科学家Yann LeCun在X平台上透露,“这篇论文曾在2023年的计算机视觉会议(CVR2023)上因‘缺少创新性’而遭到拒绝,但在2023年国际计算机视觉会议(ICCV2023)上被接受发表,并且构成了Sora的基础。”

针对有自媒体称Sora发明者之一是毕业于上海交大的天才少年谢赛宁,谢赛宁在朋友圈表示自己和Sora并没有关系,但是他也谈到,对于Sora这样的复杂系统,人才第一,数据第二,算力第三,其他都没有什么是不可替代的。

谢赛宁目前是纽约大学计算机科学助理教授,在此之前他是Facebook人工智能研究院研究科学家。
作为最懂DiT架构的人之一,在Sora发布后,谢赛宁在X平台上发表了关于Sora的一些猜想和技术解释,并表示,“Sora确实令人惊叹,它将彻底改变视频生成领域。”
“当Bill和我参与DiT项目时,我们并未专注于创新,而是将重点放在了两个方面:简洁性和可扩展性。”他写道。“简洁性代表着灵活性。关于标准的ViT,人们常忽视的一个亮点是,它让模型在处理输入数据时变得更加灵活。例如,在遮蔽自编码器(MAE)中,ViT帮助我们只处理可见的区块,忽略被遮蔽的部分。同样,Sora可以通过在适当大小的网格中排列随机初始化的区块来控制生成视频的尺寸。”

不过,他认为,关于Sora仍有两个关键点尚未被提及。一是关于训练数据的来源和构建,这意味着数据很可能是Sora成功的关键因素;二是关于(自回归的)长视频生成,Sora的一大突破是能够生成长视频,但OpenAI尚未揭示相关的技术细节。
年轻的开发团队:
应届博士带队,还有00后
随着Sora的爆火,Sora团队也来到世界舞台的中央,引发了持续的关注。OpenAI官网显示,Sora团队由William Peebles等3人领导,核心成员包括12人。从团队领导和成员的毕业和入职时间来看,这支团队成立的时间较短,尚未超过1年。

从年龄上来看,这支团队也非常年轻,两位研究负责人都是在2023年才刚刚博士毕业。William (Bill) Peebles于去年5月毕业,其与谢赛宁合著的扩散Transformer论文成为Sora的核心理论基础。Tim Brooks于去年1月毕业,是DALL-E 3的作者之一,曾在谷歌和英伟达就职。

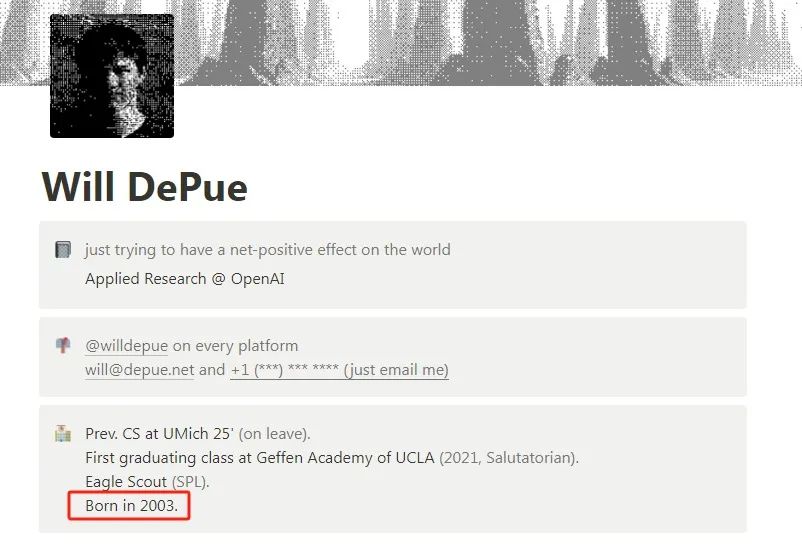
团队成员中甚至还有00后。团队中的Will DePue生于2003年,2022年刚从密西根大学计算机系本科毕业,在今年1月加入Sora项目组。
此外,团队还有几位华人。Li Jing是DALL-E 3的共同一作,2014年本科毕业于北京大学物理系,2019年获得MIT物理学博士学位,于2022年加入OpenAI。Ricky Wang则是今年1月刚刚从Meta跳槽到OpenAI。其余华人员工包括Yufei Guo等尚未有太多公开资料介绍。
(稿件来源:每经网)
 扫一扫分享本页
扫一扫分享本页



















